Abstract
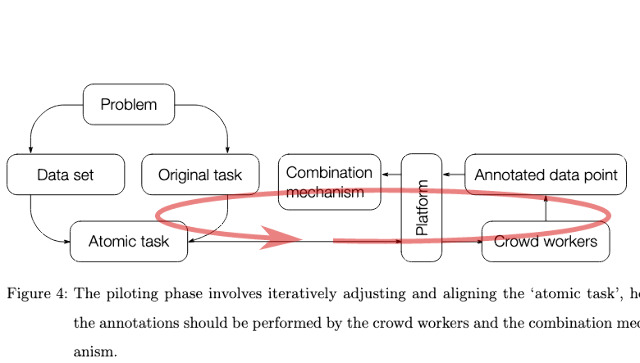
Crowdsourcing is a common approach to annotate a data set to be analysed directly or used for ‘Artificial Intelligence’ (‘AI’) applications. An initiator distributes tasks to crowd workers, who then annotate the data point. Turning to crowdsourcing exposes the initiator to multiple sources of uncertainty: How the task should be designed, who is part of the crowd, how to best make use of the annotations, and how to know if the crowd’s work is any good are causes for concern. From a Science and Technology Studies perspective, this study investigates how practitioners that crowdsource data sets address uncertainties during this process. Adopting the stance of Actor-Network Theory, this thesis analyses the actual, messy practice of building a stable actor-network that is crowdsourcing. To achieve this, I conducted qualitative interviews with practitioners and analysed them using Situational Analysis. In this study, I identify strategies to address uncertainty shared among most approaches to crowdsourcing. Among them is the decomposition of the problem into small ‘atomic tasks’. They often involve single-choice questions, which makes them amenable to calculation. If this is the case, several crowd workers can annotate each data point, and their results get combined through a mathematical aggregation mechanism. This allows the initiator to spread uncertainty across crowd workers and make it quantifiable. Finding a suitable task design for this approach is difficult and involves extensive iterative experimentation where agency shifts between the initiator, crowd, and aggregation mechanism. These aggregation mechanisms often privilege a majority while silencing crowd workers that deviate from it. The ‘atomic tasks’ have to act as faithful intermediaries. To make this possible, context information is crucial. I show in this thesis that, depending on the amount and type of context necessary, this puts a limit to task decomposition. The importance of context raises the question of how this context gets inscribed in the annotations and how this, in turn, contributes to biased data sets and potential ‘AI’ applications building on top of them. As the ‘crowd’ can be anonymous or seen as deficient compared to experts, initiators use different forms of supervision to monitor their work. An existing, small ‘ground truth’ data set with known results plays an important role here: It can be used to select ‘good’ workers upfront, or it gets used for test tasks that help evaluate the workers. Workers can also be compared to their peers. The initiator then can discipline them by excluding them and denying payment. My study shows that it is not straightforward to make crowdsourcing work but takes tremendous effort, labour that often remains invisible and hidden. At the same time, I show how epistemic approaches, whether the initiators consider the data as disputed and how this gets acknowledged, informs the structure of crowdsourcing processes.